În 2026, pe lângă căutarea clasică în Google, există rezumate AI generate automat, dar și comparații, recomandări și răspunsuri care apar direct în interfața de chat cu ChatGPT sau Gemini. Agenții AI citesc web-ul ca pe o bază de date. Indiferent că îi spui GEO, AEO sau „căutare cu AI" (en. AI Search), site-ul trebuie să fie interpretabil semantic, nu doar frumos pe toate ecranele.
Schema.org (implementată ca JSON-LD) este o investiție cu risc redus și benefică pe termen lung. Ea poate reduce ambiguitățile despre brand, produse și servicii, poate crește acuratețea cu care uneltele AI preiau informațiile și poate fi apoi reutilizată pentru SEO, feed-uri și automatizări. Despre toate acestea în acest mini-ghid.
Update: În februarie 2026 Google a publicat WebMCP (Web Model Context Protocol) ca early preview de comunicare structurată între agenții AI și site. Detaliem pe scurt WebMCP la finalul ghidului, după ce descriem schema.org ca fundație obligatorie (Sursa: Chrome for Developers)
1. SEO clasic și trecerea spre definirea entităților
În SEO clasic, avantajele se obțineau din titluri bune, headings (h1, h2 etc) coerente, viteză de încărcare crescută și multe linkuri externe de calitate. Site-urile bine structurate conform recomandărilor Google și recomandate ajungeau pe primele pagini.
În AI Search, un strat nou stă peste toate acestea: entitățile. Un sistem AI nu înțelege pagina ca motorul de căutare Google, fiind optimizat pentru a extrage informațiile de bază. Harta de bază pe care trebuie să o creeze include concepte semantice (cine / ce / ce caracteristici / în ce relații). Schema.org este metoda standard de a declara aceste lucruri fără ambiguități și AI citește entitățile definite în formatul JSON-LD:
- Sursa: proprietăți
publisher / organization - Obiectul paginii: proprietăți
product / service / article - Proprietăți principale:
author,date,additionalProperty,Offers > Offer > price, priceCurrency, availability - Relații cu restul:
sameAs,subjectOf,breadcrumb,isPartOf(ultima pentruCreativeWorkcaArticle).
Ce este Schema.org?
Vocabular comun folosit de motoare de căutare și sisteme automate pentru a înțelege conținutul: organizații, produse, servicii, articole, recenzii, evenimente, întrebări și răspunsuri etc. Se declară în programare ca JSON-LD.
Schema.org nu este un plugin și nu este un „snippet" lipit pe pagină. O implementare bună este un model de date pentru site, adică organizarea informațiilor, plus o implementare tehnică cu mare atenție.
TechArticle OPTI.RO cu câteva proprietăți ale unui ghid tehnic. Vezi în site2. De ce să implementezi schema?
„Punem schema ca să luăm rich snippets"
Deja de câțiva ani este riscantă această așteptare și nu este motivul corect pentru schema.org. Unele rich results (casete Google speciale) au fost limitate sau restrânse puternic. De exemplu, FAQ/HowTo nu mai apar la fel de frecvent și steluțele de review mai sunt disponibile doar la niște tipuri limitate, ca Product / SoftwareApplication.
Schema.org merită implementată, dar trebuie să o faci pentru scopul corect. Site-ul obține înțelegere și citabilitate, nu doar efecte vizuale în SERP. O implementare corectă aduce:
| Avantaj | Cum? |
|---|---|
| Indexare mai coerentă | Poate duce la o interpretare coerentă a paginilor descoperite de Google Search. Intervalul de indexare se poate ajusta mai rapid când modifici secțiunile site-ului. |
| Interpretare corectă a brandului și ofertelor |
Ajută mult site-urile ecommerce care conțin produse. Ajută considerabil companiile cu branduri similare cu altele de pe Internet. Pentru companiile cu mai multe site-uri (ex: în domeniul medical și farma: site părinte + site-uri de produse) indexarea va fi coerentă. |
| Rezultate mai clare | Snippeturile extrase în căutări vor fi influențate de înțelegerea corectă a domeniului și relațiilor cu alte pagini. |
| Baza de „AI readiness" | Modelul de date și entități poate fi refolosit pentru SEO (mapare cu keywords), feed-uri (ex: marketplace-uri) și alte automatizări (ex: arhitectură de date pentru AI). |
FAQ (întrebări frecvente) și HowTo (pas cu pas) rămân utile, fiind populabile în aproape orice pagină, dar nu pentru snippeturi rapide pe Google. Sunt utile ca:
- Întrebări ale clienților reali care doresc informații
- Răspunsuri scurte și verificabile pe care AI le poate citi
- Un mod de a ajuta înțelegerea paginii
Ele trebuie să existe în pagina reală (nu doar în JSON-LD) și să nu fie multe dar fără valoare, caz în care mai curând strică. Dar AI poate lua în considerare FAQ când parsează o pagină.
3. „Graph-first" - modelul de date este prioritar
Poți implementa teoretic schema.org ca în pluginurile WordPress, bucată cu bucată, punând o bucată de cod JSON-LD în fiecare pagină. Dar este și multă muncă individuală, și lipsă de adaptare la schimbările viitoare, și dificultate crescută în a defini relațiile între pagini: care sunt categorii de produse, care sunt produse individuale conținute, care sunt condițiile comerciale de vânzare.
Soluția este să definești modelul de date și să-l realizezi ca graf (en. graph) coerent, de exemplu:
- o entitate
Organization(cu un@idstabil) - un
WebSite(cupublisher = Organization) - pagini (
WebPage) care se leagă la Organization prinpublisherși la Website prinisPartOf - produse (
Product/SoftwareApplication) care se leagă la Organization prinpublisher/manufacturer - servicii (
Service) care se leagă la Organization prinprovider - articole (
Article/TechArticle) care se leagă lapublisher/author - serii (
CreativeWorkSeries) care leagă articolele între ele - etc…
De ce contează @id la aproape orice entitate
@id este „cheia" care spune: asta e aceeași entitate peste tot. Când ai mai multe site-uri pentru aceeași organizație sau producător, doar @id declarat în schema.org asigură că ele sunt tratate ca ținând de aceeași companie. Fără ID-uri stabile, apar dubluri: aceeași entitate va fi descrisă în zece moduri ușor diferite. Asta duce la rezultate divergente în căutări.
O practică universală de numire @id este URL + hash, de exemplu https://site.com/#organization
Din practică: refolosiți aceleași entități.
În proiectele reale, Organization, WebSite și paginile cheie folosesc aceleași ID-uri stabile, iar serviciile/produsele/articolele se leagă de același nucleu semantic. Este dificil de creat inițial, dar aduce rezultate.
Vezi studiul nostru de caz (implementare completă și exemple)
Minimul de proprietăți pe care îl poți implementa
Dacă ai resurse limitate, acesta e setul cu cele mai bune rezultate:
| Entitate în schema.org | Proprietăți |
|---|---|
OrganizationUna singură, sigur în Acasă, Despre noi, știri etc |
|
WebSiteUnul singur, link în toate paginile |
|
WebPagePaginile cheie (care nu sunt de produs, serviciu, știri etc) |
|
BreadcrumbListPe fiecare pagină |
Pentru orice site cu structură: categorii, servicii, secțiuni, produse. Ajută atât navigarea, cât și contextul semantic. |
4. Pentru B2B: cum faci AI să înțeleagă serviciile tale?
Multe site-uri B2B (elearning, service, execuție, servicii medicale, marketing etc) au o problemă clasică. Serviciile lor sunt descrise în paragrafe de text, deseori în cadrul unui zid de text (en. wall of text). Pentru AI, un paragraf e greu de comparat cu alt paragraf, deci nu înțelege dacă serviciul oferit este exact ce caută utilizatorul.
În schema.org este recomandat să folosești Service pe paginile de servicii și să adaugi proprietățile care structurează potențiala ofertă.
Implementare pentru aproape orice serviciu
| Componentă | Proprietăți |
|---|---|
| Proprietăți directe |
|
|
Alte capabilități tehnologiile, metodologia urmată, industriile (verticalele), livrabilele |
|
|
Credibilitatea serviciului Legare de conținut de tip știre, studiu de caz, pagini de proiect |
|
Implementare pentru produse software
Dacă vinzi software (SaaS, licențe, pachete), tratează paginile ca entități clare.
Proprietăți SoftwareApplication sau Product (cu modificări) — în funcție de context |
|---|
|
Ca la FAQ/HowTo, cea mai importantă este consistența între ce afișezi și ce declari în JSON-LD. Dacă schema declară un preț sau un testimonial (review), pe pagină trebuie să existe acel preț sau modul de calcul și acel testimonial. Orice markup invizibil mai curând strică.
SoftwareApplication opti.ro5. Pentru e-commerce: ce implementări fac diferența pentru vânzări?
Magazinele online sunt cele unde schema poate fi extraordinar de utilă, dar și unde se greșește cel mai des.
Produsele trebuie detaliate în amănunțime. Pagina de categorie, căutare sau persoană corelată (autor, influencer etc) este o listă ordonată care trebuie declarată ca atare.
| Entitate în schema.org | Proprietăți |
|---|---|
ProductCel mai important |
|
ItemListpentru paginile de listare |
|
Se clarifică astfel ce produse sunt pe paginile respective și AI va înțelege mai ușor și cu mai puține halucinații magazinul online.
Foarte important, ca în toate cazurile dar mai ales pentru e-commerce, schema trebuie generată automat din date reale, altfel va fi în urma dinamicii site-ului.
Checklist e-commerce 2026:
- Product legat la Organization și WebSite
- ItemList pe listări
- BreadcrumbList în tot site-ul și SearchAction pe WebSite
- Generare automată server-side
Pentru un exemplu și structură extra pentru magazinele de carte vezi studiul de caz
6. Cum vedem beneficiile?
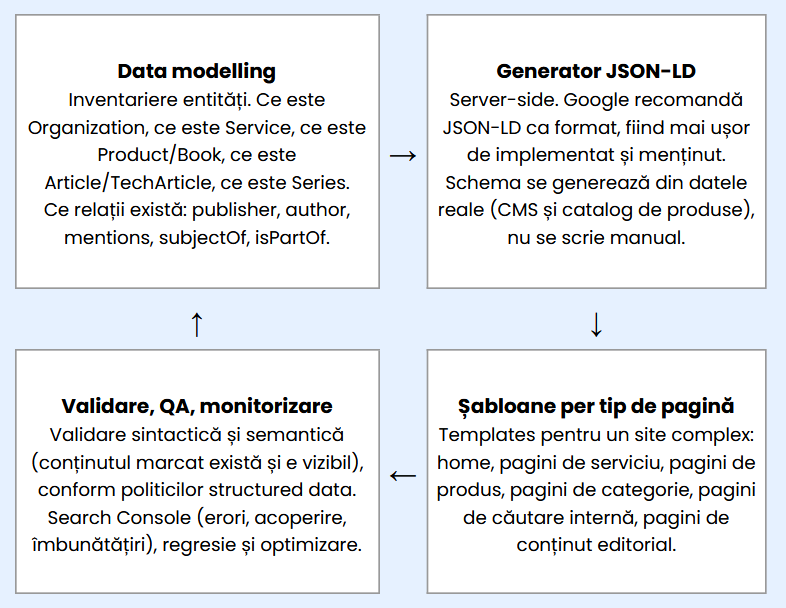
Implementarea profesionistă
O implementare profesionistă arată ca un mini-proiect software, cu faze tehnice prin care trebuie să treci obligatoriu până se ajunge la codarea efectivă. În studiul nostru de caz identificăm patru stadii:
- Data modelling
- Generare
JSON-LDserver side - Șabloane per tip de pagină
- Validare, QA, monitorizare
Semnalele de trafic
Google declară oficial (contra unor zvonuri persistente) că ordinea în căutarea clasică nu este afectată de implementarea schema.org. Deci nu există o garanție că schema va aduce +x% trafic imediat. Dar în practică, rezultatele care sunt mai bine înțelese sunt mai bine afișate și în GEO / AI Search asta contează enorm.
Poți urmări în Google Search Console:
- Scăderea erorilor și warning-urilor de structured data din GSC
- Stabilitate în numărul de pagini indexate și în ritmul de indexare
- Stabilitate la recrawl / volatilitate.
Semnale SEO (Google Search Console)
- Creșterea impresiilor pe zona long-tail, de ex: servicii / categorii
- Creșterea CTR pe pagini, de ex: prin breadcrumbs afișate în căutare
- Creșterea vizibilității pe interogări non-brand
Semnale GEO (manual prin sondaj)
- Mențiuni corecte ale brandului și ofertelor în rezumatele AI
- Citări ale paginilor grele de conținut: servicii, produse, ghiduri
- Reducerea confuziilor între produse, ediții și variante.
Câteva capcane și greșeli comune în implementare
- Dubluri de
Organizationfără@idstabil. - Schema care nu reflectă conținut vizibil.
- Preț/stoc/alte proprietăți declarate greșit, de exemplu dacă sunt hard-codate.
- Review/aggregateRating inventate fără conținut vizibil.
- FAQ interminabile
- Amestec de tipuri nejustificat, de ex.
Productpe pagină de serviciu. - Lipsa legăturilor, de ex. între servicii și dovezi: articole, știri, studii de caz.
- Generarea asincronă via pluginuri JavaScript (client-side) care poate fi prea lentă
Dacă le eviți pe acestea ești în top 90%.
O nuanță foarte importantă pentru EEAT (autoritate și experiență) este ca persoanele să fie entități (Person) cu link (sameAs) către profilele sociale, nu doar text, de exemplu la author pentru știri, ghiduri și alte materiale.
Dacă anii trecuți schema.org era un plus, din 2025 și 2026 ea devine aproape obligatorie pentru site-urile care vor să fie interpretate coerent de motoare de căutare și sisteme AI. Ceea ce îți dă mai mult control, asigură o bază solidă pentru SEO și un avantaj competitiv clar într-o piață în care crearea de conținut nu mai este suficientă, în urma avansului chatGPT.
Nou: WebMCP și web-ul „agent-ready"
Schema.org descrie clar cine ești și ce conținut ai (entități, proprietăți, relații), WebMCP va descrie ce poate face un agent AI pe site-ul tău, într-un mod predictibil.
În februarie 2026, echipa Google a publicat WebMCP ca early preview. În loc ca agenții AI să ghicească interacțiunile pe web unde există DOM parsing, screenshot-uri, click-uri fragile, site-urile vor putea expune un set de acțiuni permise pe care un agent le poate apela.
Vor fi două direcții pentru acțiuni:
- o zonă declarativă: pentru acțiuni standard, ușor de descris în jurul formularelor
- o zonă imperativă: pentru interacțiuni dinamice, care cer JavaScript și parametri mai bogați
Va fi mai multă robustețe după implementarea WebMCP, pentru că tool-urile rămân stabile când UI (grafic) se schimbă, deci interacțiunile cu agentul AI nu vor fi amenințate de fiecare redesign. Este și o punte către viitorul „comerț agentic" și „suport agentic": căutare de produse, configurări, ticketing, rezervări, toate vor putea fi apeluri structurale, fără clicuri umane.
Pe scurt, Schema.org îi explică agentului AI cine ești și ce vinzi (contextul semantic), iar WebMCP îi va permite să acționeze (să adauge în coș, să ceară o ofertă). Sunt două tehnologii complementare pentru web-ul viitorului.
Vrei o implementare „graph-first" pe site-ul tău?
Putem face pentru site-ul tău exact ceea ce am descris în acest ghid. Dacă ai un site B2B sau un eCommerce și vrei să fie AI-ready, contactează-ne aici.