





In 2026, alongside classic Google search, there are auto-generated AI summaries, comparisons, recommendations and answers that appear directly in the chat interfaces of ChatGPT or Gemini. AI agents read the web like a database. Whether you call it GEO, AEO or "AI Search", your site needs to be semantically interpretable, not just visually polished across all screens.
Schema.org (implemented as JSON-LD) is a low-risk, long-term investment. It can reduce ambiguities about your brand, products and services, improve the accuracy with which AI tools extract your information, and be reused for SEO, feeds and automations. This mini-guide covers all of that.
Update: In February 2026 Google published WebMCP (Web Model Context Protocol) as an early preview for structured communication between AI agents and websites. We briefly cover WebMCP at the end of this guide, after describing schema.org as the mandatory foundation (Source: Chrome for Developers)
1. Classic SEO and the shift toward entity definition
In classic SEO, gains came from strong titles, coherent headings (h1, h2, etc.), fast load times and many quality external links. Well-structured sites that followed Google's recommendations and earned backlinks reached the top pages.
In AI Search, a new layer sits on top of all that: entities. An AI system does not read a page the way Google's crawler does; it is optimized to extract core information. The basic map it needs to build includes semantic concepts (who / what / what properties / what relationships). Schema.org is the standard way to declare these things without ambiguity, and AI reads the entities defined in JSON-LD format:
- Source:
publisher / organizationproperties - Page subject:
product / service / articleproperties - Main properties:
author,date,additionalProperty,Offers > Offer > price, priceCurrency, availability - Relationships:
sameAs,subjectOf,breadcrumb,isPartOf(the last one forCreativeWorksuch asArticle).
What is Schema.org?
A shared vocabulary used by search engines and automated systems to understand content: organizations, products, services, articles, reviews, events, Q&A, and more. It is declared in code as JSON-LD.
Schema.org is not a plugin and it is not a "snippet" pasted onto a page. A good implementation is a data model for the site, meaning the organization of information, combined with a technical implementation done with great care.
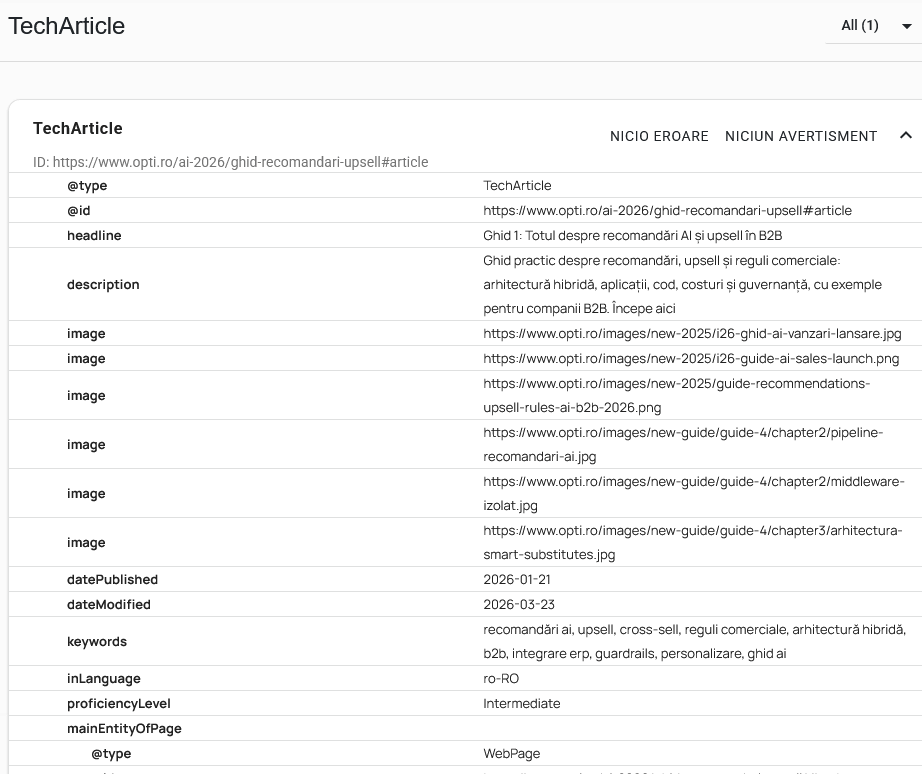
TechArticle schema on OPTI.RO with a few properties of a technical guide. See it on the site2. Why implement schema?
"We add schema to get rich snippets"
This expectation has been risky for several years now and it is not the right reason to implement schema.org. Some rich results (special Google boxes) have been limited or significantly scaled back. For example, FAQ/HowTo no longer appear as frequently, and review stars are now available only for a limited set of types such as Product / SoftwareApplication.
Schema.org is worth implementing, but you need to do it for the right reason. Your site gains understanding and citability, not just visual effects in the SERP. A correct implementation brings:
| Benefit | How? |
|---|---|
| More coherent indexing | Can lead to a more coherent interpretation of pages discovered by Google Search. The indexing interval can adjust more quickly when you modify sections of the site. |
| Correct interpretation of brand and offerings |
Greatly helps ecommerce sites that contain products. Considerably helps companies whose brand names are similar to others on the Internet. For companies with multiple sites (e.g. in the medical and pharma space: parent site + product sites) indexing will be consistent. |
| Clearer results | Snippets extracted in searches will be influenced by a correct understanding of the domain and its relationships with other pages. |
| Foundation for "AI readiness" | The data model and entities can be reused for SEO (keyword mapping), feeds (e.g. marketplaces) and other automations (e.g. data architecture for AI). |
FAQ (frequently asked questions) and HowTo (step-by-step) remain useful and can be added to almost any page, but not for quick Google snippets. They are useful as:
- Questions from real customers who want information
- Short, verifiable answers that AI can read
- A way to help the page be understood
They must exist in the actual page (not only in JSON-LD) and should not be numerous but valueless, in which case they do more harm than good. AI can, however, take FAQ into account when parsing a page.
3. "Graph-first" - the data model comes first
You could theoretically implement schema.org the way WordPress plugins do it, piece by piece, adding a JSON-LD block to each page. But that approach involves a lot of individual effort, poor adaptability to future changes, and growing difficulty in defining relationships between pages: which are product categories, which are individual products within them, what are the commercial terms of sale.
The solution is to define a data model and build it as a coherent graph, for example:
- one
Organizationentity (with a stable@id) - one
WebSite(withpublisher = Organization) - pages (
WebPage) linked to Organization viapublisherand to WebSite viaisPartOf - products (
Product/SoftwareApplication) linked to Organization viapublisher/manufacturer - services (
Service) linked to Organization viaprovider - articles (
Article/TechArticle) linked topublisher/author - series (
CreativeWorkSeries) that link articles together - etc.
Why @id matters for almost every entity
@id is the "key" that says: this is the same entity everywhere. When you have multiple sites for the same organization or manufacturer, only the @id declared in schema.org ensures they are treated as belonging to the same company. Without stable IDs, duplicates appear: the same entity gets described in ten slightly different ways, leading to divergent results in searches.
A universal @id naming convention is URL + hash, for example https://site.com/#organization
From practice: reuse the same entities.
In real projects, Organization, WebSite and key pages use the same stable IDs, and services, products and articles all link back to the same semantic core. It is difficult to set up initially, but it delivers results.
The minimum set of properties you can implement
If your resources are limited, this is the set that delivers the best results:
| Entity in schema.org | Properties |
|---|---|
OrganizationJust one, definitely on Home, About, news pages, etc. |
|
WebSiteJust one, linked from all pages |
|
WebPageKey pages (that are not product, service, or news pages) |
|
BreadcrumbListOn every page |
For any site with structure: categories, services, sections, products. Helps both navigation and semantic context. |
4. For B2B: how do you make AI understand your services?
Many B2B sites (elearning, maintenance, execution, medical services, marketing, etc.) share a classic problem. Their services are described in text paragraphs, often forming a wall of text. For AI, one paragraph is hard to compare with another, so it cannot determine whether the service offered is exactly what the user is looking for.
In schema.org it is recommended to use Service on service pages and add the properties that structure the potential offering.
Implementation for almost any service
| Component | Properties |
|---|---|
| Direct properties |
|
|
Other capabilities technologies, methodology, industries (verticals), deliverables |
|
|
Service credibility Linking to news, case studies, project pages |
|
Implementation for software products
If you sell software (SaaS, licenses, packages), treat the pages as clear entities.
SoftwareApplication or Product properties (with adjustments) - depending on context |
|---|
|
As with FAQ/HowTo, the most important thing is consistency between what you display and what you declare in JSON-LD. If the schema declares a price or a testimonial (review), that price or its calculation method and that testimonial must be visible on the page. Any invisible markup is more likely to cause harm than good.

SoftwareApplication schema example on opti.ro5. For e-commerce: which implementations make a difference for sales?
Online stores are where schema can be extraordinarily useful, but also where mistakes are most common.
Products need to be described in detail. A category page, a search results page, or a person-related page (author, influencer, etc.) is an ordered list that must be declared as such.
| Entity in schema.org | Properties |
|---|---|
ProductThe most important |
|
ItemListfor listing pages |
|
This clarifies which products are on those pages and AI will understand the online store more easily and with fewer hallucinations.
Very importantly, as in all cases but especially for e-commerce, schema must be generated automatically from real data, otherwise it will lag behind the site's dynamic state.
E-commerce checklist 2026:
- Product linked to Organization and WebSite
- ItemList on listing pages
- BreadcrumbList site-wide and SearchAction on WebSite
- Automatic server-side generation
For an example and extra structure for book stores, see the case study
6. How do we see the benefits?
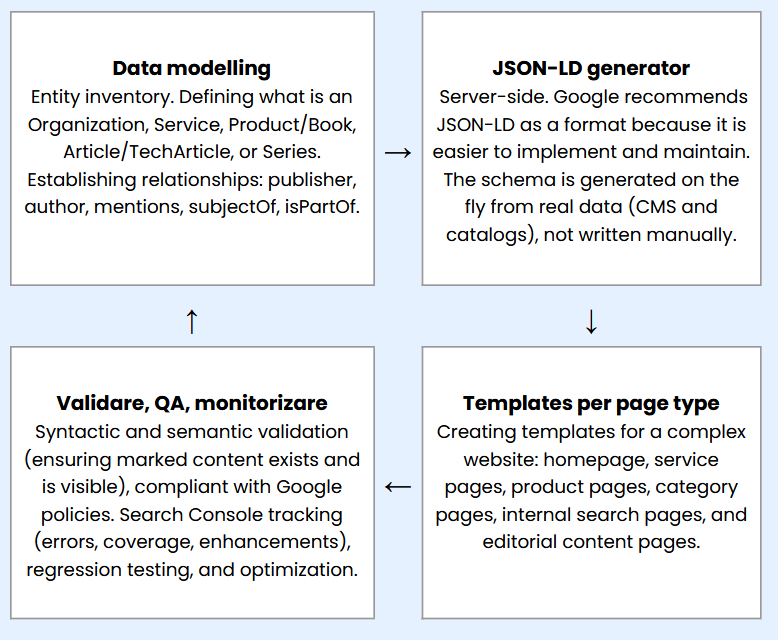
Professional implementation
A professional implementation looks like a mini software project, with technical phases you must go through before reaching the actual coding. In our case study we identify four stages:
- Data modelling
- Server-side
JSON-LDgeneration - Templates per page type
- Validation, QA, monitoring
Traffic signals
Google officially states (against persistent rumors) that ranking in classic search is not affected by implementing schema.org. So there is no guarantee that schema will bring +x% traffic immediately. But in practice, results that are better understood are better displayed, and in GEO / AI Search that matters enormously.
You can monitor in Google Search Console:
- Reduction in structured data errors and warnings in GSC
- Stability in the number of indexed pages and the pace of indexing
- Stability at recrawl / lower volatility.
SEO signals (Google Search Console)
- Growth in impressions on the long-tail, e.g. services / categories
- Growth in CTR on pages, e.g. through breadcrumbs shown in search
- Growth in visibility on non-brand queries
GEO signals (manual sampling)
- Correct mentions of the brand and offerings in AI summaries
- Citations of content-heavy pages: services, products, guides
- Fewer confusions between products, editions and variants.
Common pitfalls and mistakes in implementation
- Duplicate
Organizationentities without a stable@id. - Schema that does not reflect visible content.
- Incorrectly declared price/stock/other properties, for example when hard-coded.
- Invented review/aggregateRating without visible content.
- Endless FAQs
- Unjustified mixing of types, e.g.
Producton a service page. - Missing links, e.g. between services and supporting evidence: articles, news, case studies.
- Asynchronous generation via JavaScript plugins (client-side) that may be too slow
If you avoid these, you are in the top 90%.
One very important nuance for E-E-A-T (authority and experience) is that people should be entities (Person) with a link (sameAs) to their social profiles, not just plain text, for example in the author field for news, guides and other materials.
If in previous years schema.org was a bonus, from 2025 and 2026 onward it is becoming almost mandatory for sites that want to be interpreted coherently by search engines and AI systems. This gives you more control, provides a solid SEO foundation, and offers a clear competitive advantage in a market where content creation alone is no longer enough, given the rise of ChatGPT.
New: WebMCP and the "agent-ready" web
Schema.org clearly describes who you are and what content you have (entities, properties, relationships). WebMCP will describe what an AI agent can do on your site, in a predictable way.
In February 2026, the Google team published WebMCP as an early preview. Instead of AI agents guessing interactions on the web through DOM parsing, screenshots, and fragile clicks, sites will be able to expose a set of permitted actions that an agent can call.
There will be two directions for actions:
- a declarative layer: for standard actions, easy to describe around forms
- an imperative layer: for dynamic interactions that require JavaScript and richer parameters
WebMCP will bring greater robustness because tools remain stable when the UI changes, so interactions with the AI agent will not be threatened by every redesign. It is also a bridge toward the future of "agentic commerce" and "agentic support": product searches, configurations, ticketing, bookings will all be able to become structured calls, without human clicks.
In short, Schema.org explains to the AI agent who you are and what you sell (the semantic context), while WebMCP will let it act (add to cart, request a quote). They are two complementary technologies for the web of the future.
Want a "graph-first" implementation on your site?
We can do for your site exactly what we described in this guide. If you have a B2B site or an eCommerce and want it to be AI-ready, contact us here.





